


When it comes to automatically classifying digital files and documents based on their content (for example marking a document including a person’s medical information as Confidential), we generally look to a technique called “pattern matching.” This is by far the most common approach, but while this method is a useful starting point and provides valuable insights, it is far from the panacea that you might initially expect.
In this blog post, I’m going to explain the reasoning behind this and provide some recommendations on how to tackle automated data classification of unstructured data.
While automated classification techniques, including pattern matching, work well for structured data stored in databases, unstructured data presents unique challenges that I plan to cover here.
Let’s Start with Pattern Matching

Pattern matching, as the name suggests, involves defining a particular pattern of characters which you then look for within a document – describe a distinctive pattern of characters, and I can write an ‘expression’ to find that pattern wherever it exists in the data you choose to scan.
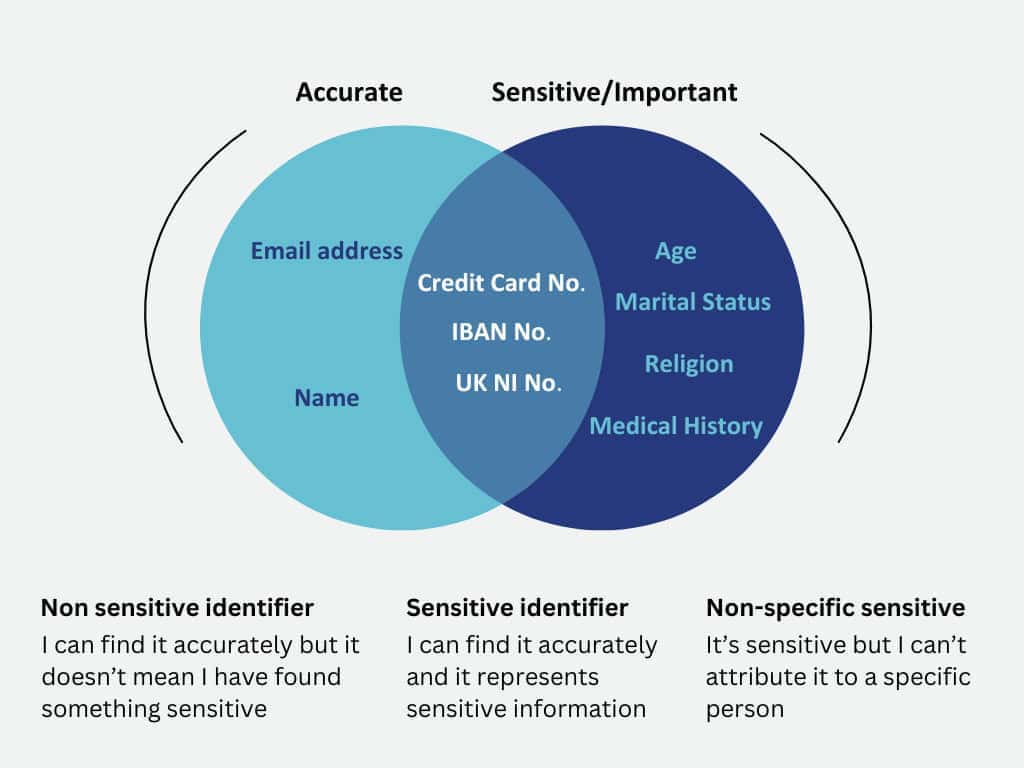
The big issue around this is the use of the word ‘distinctive.’ This technique works well for patterns that are highly specific, such as UK National Insurance numbers, which always start with two letters, followed by six numbers, and end with a single letter. Anything matching this pattern is almost certainly an NI number, and anything not matching it likely isn’t.
That brings us to the question…but what about everything else?
Consider how GDPR defines Special Category Data: it includes information related to your health, religious beliefs, sexual orientation, and ethnic background. How would you capture references to religious beliefs using pattern matching? The only approach I’ve come across so far is to create a list of words or terms that indicate the text is discussing religious beliefs, such as “Catholic” or “Muslim,” and match for those specific words. However, this method has its own shortcomings. First, the appearance of these words does not reliably identify Special Category Data. The words themselves are not inherently sensitive; we are only interested in them because they might indicate sensitive information (in this case relating to the religious beliefs of a specific individual). Second, we would miss any Special Category data that does not explicitly use the words we have thought of. As a result, this approach often leads to massive inaccuracies – and unfortunately, it’s an issue that is fairly abundant in the sorts of things we consider to be sensitive.

This is not really the fault of the software – imagine trying to explain specifically exactly how to someone should decide if a document is sensitive or not without any context.
Now let’s consider email addresses. They are actually very distinctive and pattern matching is very effective at accurately finding them. On the face of it, this seems like a great candidate for discovery, but once you have a set of data telling you where you have email addresses in different documents, you suddenly discover it’s not actually incredibly useful. By themselves, email addresses are not particularly sensitive. Additionally, they are everywhere, appearing in countless files. Therefore, identifying that you have thousands of files containing email addresses does not provide any meaningful benefit.
In reality, there are very few data elements that you can use pattern matching for which are both accurate and significant, so on its own, pattern matching falls a bit short.
It’s still useful…
Pattern matching alone does still provide value. What I’ve described highlights some deficiencies in using it to identify specific files which may be of concern but if you step back and consider perhaps an entire file server or file share, you can get an indication of what sort of data types might be where. This can be useful in the initial stages to build a rough map of where sensitive data might be and confirm or disprove any existing assumptions.
We had an experience where simple classification identified that there was a raft of financial information in a certain area of a file system because bank details, etc., were found there using pattern matching. This was flagged as a potential risk, prompting a manual investigation. The investigation revealed that the data posed a significant risk, which was subsequently addressed, much to the relief of the chief risk officer..
But in order to accurately call out specific files accurately…
So, pattern matching on its own is not a reliable way of identifying sensitive files and documents, but what is the solution?
There are a few additional discovery techniques that you can apply which, in the right combinations, can significantly improve the accuracy of classifying individual files. However, it does result in several, essentially bespoke solutions for different use cases.
For example, a subset of the documents where pattern matching would find financial data could be spreadsheets full of customer bank details. This sort of file would be very sensitive for obvious reasons. How can we tune discovery to filter out this sort of file from all the others that pattern matching would return based on containing financial information?
- These files would have many ‘hits’ (versus, for example, someone’s expenses claim form which you would want to classify differently) – tuning the policy based on the number of findings per file would help.
- These files would relate to financial details relating to customers specifically rather than, synthetic financial details which might be being used for testing. Using entity-based discovery to distinguish between known entities and others would help.
- These files may be particular file types – Excel spreadsheets are probably the most likely. Tuning the policy based on file type would help.
- We can also focus on where these files present the highest risk – it may be the case that these types of files are expected and necessary in certain places and therefore finding them there is no surprise or problem. Focus could be applied to those storage areas where this type of data should not be (for eg., any Microsoft Teams sites that are shared with external parties), which may also help.
You can see how it can become a bit of an art to create the right recipe of techniques (which really equates to your policy logic) to determine the best way to accurately find real issues.
Final Thoughts
Pattern matching should always be the first consideration when trying to identify sensitive files and documents in your unstructured data, but unfortunately it has its limitations. Fortunately, other techniques are available and can be applied in different combinations to zero in on different types of sensitive data to accurately classify and manage your sensitive data and protect your organisation from risks associated with any loss of confidentiality.
At Nephos, we combine technical expertise and the strategic business value of traditional professional service providers to deliver innovative data solutions. Whether you’re looking to enhance your current data classification strategy or need a partner to guide you through implementing a robust data protection framework, we stand ready to help. Click through to learn more about how we can support your data security needs.



